What is hive in big data: Hive in Big Data is a data warehousing infrastructure based on Apache Hadoop. It provides a way to query large datasets stored in Hadoop’s HDFS (Hadoop Distributed File System) using SQL-like queries called HiveQL.
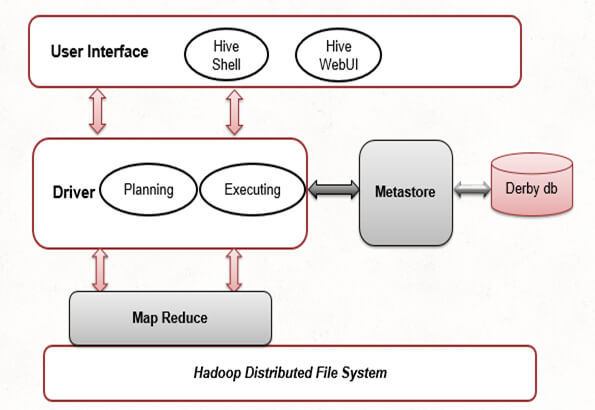
Hive translates these queries into MapReduce or Tez jobs, allowing for the analysis of big data without needing to write complex MapReduce programs.
Key Points:
- Data Warehousing: Hive is used for data warehousing, which involves collecting, managing, and analyzing large sets of structured and semi-structured data.
- SQL-Like Queries: HiveQL, the query language used in Hive, resembles SQL (Structured Query Language), making it easier for users familiar with SQL to work with Hive.
- MapReduce or Tez Jobs: Hive translates queries into MapReduce or Tez jobs, which are then executed on the Hadoop cluster, enabling parallel processing of data.
- Schema on Read: Unlike traditional databases that use Schema on Write (where data schema is defined before writing data), Hive uses Schema on Read, allowing for flexibility in data processing.
- Integration with Hadoop Ecosystem: Hive integrates with other components of the Hadoop ecosystem, such as HBase, Pig, and Spark, making it a versatile tool for big data processing.
Conclusion:
In conclusion, Hive in Big Data is a powerful tool for querying and analyzing large datasets stored in Hadoop. Its SQL-like interface, support for MapReduce and Tez, and integration with the Hadoop ecosystem make it an essential component in the big data analytics pipeline.
Introduction:
In the world of data, there are numerous tools and technologies that are used to store, process and analyze vast amounts of information. One such tool is Hive, which is widely used in big data applications. In this article, we will delve into the concept of Hive, its features, and how it fits into the world of big data.
What is Hive?
Hive is an open-source data warehouse software tool built on top of Apache™ Hadoop® used for data processing, querying, and analysis. Developed by Facebook, it was later donated to the Apache Software Foundation. Hive was primarily built to bring SQL-like querying capabilities to Hadoop, making it easier for traditional SQL users to work with big data.
Features of Hive:
1. SQL-Like Language: One of the key features of Hive is its support for SQL-like querying language, called HiveQL. This allows traditional SQL users to write queries and perform analytics on Hadoop data without the need to learn new languages or tools.
2. Scalability: Hive is highly scalable, making it ideal for handling large datasets. It can store petabytes of data and run queries in parallel, making it a perfect fit for big data applications.
3. Data Type Support: Hive supports a wide range of data types, including primitive types, complex types like arrays, and maps. This ensures that users can store and analyze various types of data without any restrictions.
4. Data Partitioning: Hive allows data to be partitioned based on a specific column, making data retrieval faster and more efficient. This is particularly useful in scenarios where large datasets need to be processed and analyzed quickly.
5. Extensibility: Hive is highly extensible, allowing developers to write their custom plug-ins and functions to enhance its capabilities further.
How Hive fits into the world of big data:
Hive is an essential component of the Hadoop ecosystem, which is widely used in big data applications. It serves as a data warehouse or computing layer for Hadoop, allowing users to query and analyze data stored in HDFS (Hadoop Distributed File System). Hive works with other tools such as Spark and Kafka to ingest data from various sources, process it, and store it in HDFS for further analysis.
Moreover, Hive complements the analytical capabilities of other big data technologies such as Apache Spark, making it easier for Data Scientists and Analysts to work with data. Hive can also integrate with existing Business Intelligence (BI) and data visualization tools, allowing organizations to gain insights from data in a more user-friendly manner.
Conclusion:
In conclusion, Hive is a powerful data warehousing tool for big data applications. Its ability to handle large datasets, support for SQL-like querying, and integration with other tools make it a go-to choice for developers and organizations looking to leverage the power of big data. With its continuous development and focus on making data analytics more accessible, Hive is undoubtedly one of the key players in the world of big data.