Hadoop architecture in big data: In the realm of big data, understanding the architecture of Hadoop is crucial. Hadoop is an open-source framework that facilitates the processing of large datasets across distributed computing environments. Let’s delve into its architecture to grasp its functioning better.
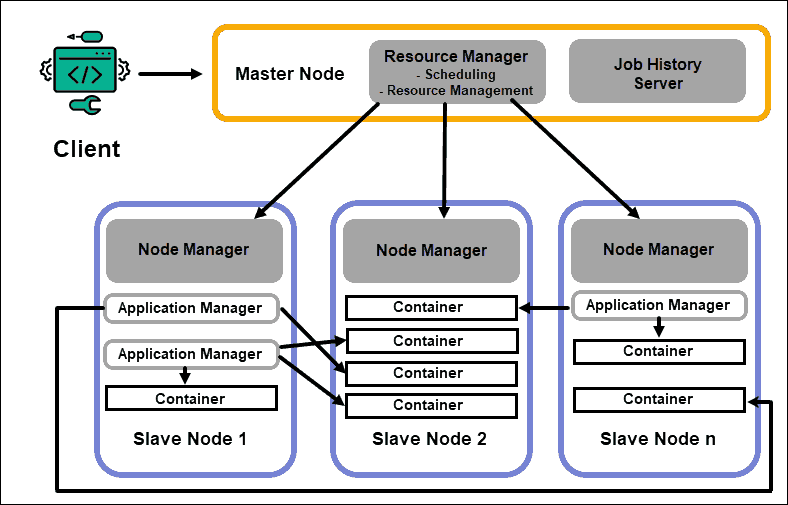
Firstly, Hadoop comprises two core components: the Hadoop Distributed File System (HDFS) and Yet Another Resource Negotiator (YARN). HDFS is responsible for storing data across multiple machines in a distributed manner, ensuring both redundancy and scalability. YARN, on the other hand, manages resources and schedules tasks across the cluster.
At the heart of Hadoop’s architecture lies the concept of master-slave architecture. The master node oversees the entire cluster and coordinates the execution of tasks, while the slave nodes perform the actual data processing tasks. This distributed model enables Hadoop to handle vast amounts of data efficiently.
Another essential aspect of Hadoop architecture is its fault tolerance mechanism. Hadoop ensures fault tolerance by replicating data across multiple nodes in the cluster. In the event of a node failure, data can be retrieved from other replicas, ensuring minimal disruption to data processing operations.
Furthermore, Hadoop supports a programming model known as MapReduce, which simplifies the processing of large datasets by dividing them into smaller chunks and processing them in parallel across the cluster. This approach enhances both scalability and performance.
In addition to its core components, Hadoop ecosystem includes various modules and tools that extend its functionality. These modules cater to different aspects of data processing, storage, and analysis, such as Apache Hive for data warehousing, Apache Spark for real-time processing, and Apache HBase for NoSQL database capabilities.
Overall, the architecture of Hadoop in big data is designed to tackle the challenges posed by large-scale data processing. By leveraging distributed computing and fault tolerance mechanisms, Hadoop enables organizations to extract valuable insights from massive datasets efficiently and cost-effectively.
Hadoop Architecture in Big Data: A Comprehensive Analysis
In today’s digital world, we are constantly inundated with a large amount of data, commonly referred to as “big data”. This data contains valuable information that can be used for various purposes, such as making business decisions, understanding customer behavior, and predicting future trends. However, the sheer volume and complexity of big data has posed a significant challenge for traditional data processing systems. As a result, there has been a growing need for innovative solutions that can effectively handle and analyze big data. One such solution is Hadoop, an open-source distributed processing framework for big data. In this article, we will delve into the architecture of Hadoop and its role in handling big data.
Hadoop was created in 2006 by Doug Cutting and Mike Caferella, with the goal of designing a scalable framework for processing large-scale data sets. It has since become the go-to platform for companies to handle their data processing needs, with over 50% of Fortune 500 companies adopting it. Hadoop’s success can be attributed to its unique architecture, which is based on two main components – Hadoop Distributed File System (HDFS) and MapReduce.
HDFS is the underlying file system that stores and manages data in Hadoop. It is designed to be fault-tolerant, meaning it can handle hardware failures without any disruption in data access. It is also highly scalable, allowing data to be stored on multiple nodes in a cluster. This distributed storage approach ensures efficient utilization of resources and enables Hadoop to handle petabyte-scale data sets.
MapReduce is the programming model and execution engine responsible for processing data stored in HDFS. Its primary function is to distribute the processing of data across multiple nodes in the cluster, making it a highly scalable and efficient way of handling large data sets. In a MapReduce job, the data is divided into smaller chunks, and each chunk is processed independently on a different node. After processing, the results are combined and returned, resulting in faster processing times compared to traditional systems.
Hadoop architecture also includes additional components such as Hadoop Common, YARN (Yet Another Resource Negotiator), and Hadoop Ecosystem. Hadoop Common is a collection of libraries and utilities used by other Hadoop modules, while YARN is responsible for managing resources and jobs in a Hadoop cluster. The Hadoop Ecosystem consists of various tools and frameworks that work with Hadoop to provide a complete data processing and analytics solution. Some popular tools in the Hadoop ecosystem include Apache Hive, HBase, Spark, and Pig.
One of the key advantages of Hadoop architecture is its ability to handle various data formats. Unlike traditional systems, which are limited to handling structured data, Hadoop can process structured, unstructured, and semi-structured data such as text, images, videos, and log files. This capability has made Hadoop a popular choice for big data analytics, as it allows organizations to extract insights from diverse data sources.
In addition to its ability to handle diverse data, Hadoop’s architecture also addresses the challenge of data redundancy. Traditional data processing systems usually require multiple copies of data to handle concurrent access, which results in significant storage costs. In contrast, Hadoop stores data in a distributed manner, eliminating the need for data duplication. The distributed approach also facilitates data backup and recovery, ensuring data availability in case of hardware failure.
In conclusion, Hadoop’s architecture has revolutionized the way big data is handled and has become an essential tool for organizations dealing with massive amounts of data. Its scalable and fault-tolerant design, coupled with the ability to process various data formats, has made it a popular choice for data processing and analysis. As the volume and complexity of big data continue to grow, Hadoop is expected to play a significant role in the future of data management.