Hadoop ecosystem in big data: In today’s data-driven world, managing and analyzing vast amounts of information is essential for businesses to thrive. This is where the Hadoop ecosystem comes into play, offering a comprehensive suite of tools to tackle big data challenges effectively.
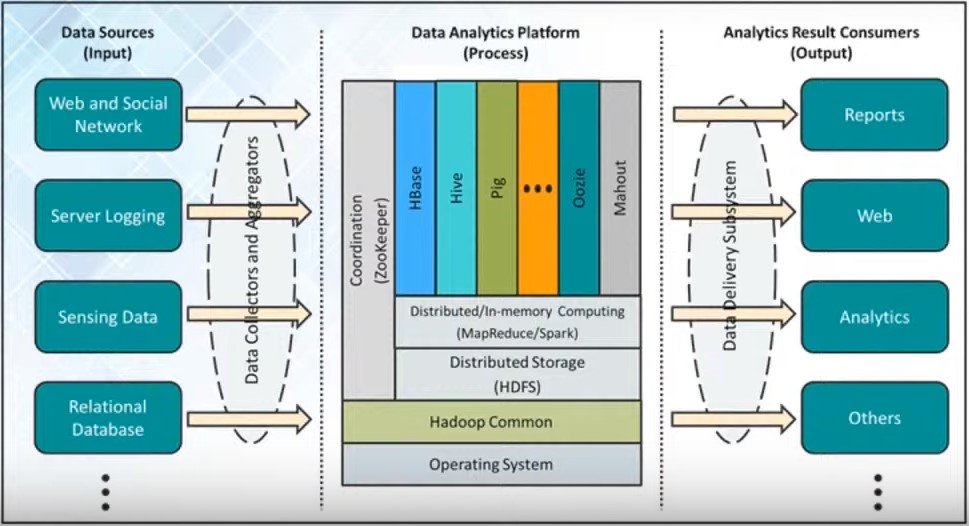
Let’s delve into the key components of the Hadoop ecosystem and understand how they work together to process, store, and analyze massive datasets.
Hadoop, at its core, is an open-source framework that facilitates distributed storage and processing of large datasets across clusters of computers. It comprises several interconnected components, each serving a specific purpose in the big data pipeline.
The first component is Hadoop Distributed File System (HDFS), which acts as the storage layer of the ecosystem. HDFS divides large files into smaller blocks and distributes them across multiple nodes in a cluster, ensuring high availability and fault tolerance.
Next up is MapReduce, a programming model and processing engine for distributed computing. MapReduce allows users to write parallelizable algorithms to process data stored in HDFS. It consists of two main phases: the Map phase, where data is filtered and sorted, and the Reduce phase, where computation results are aggregated.
Beyond HDFS and MapReduce, the Hadoop ecosystem offers a plethora of complementary tools and frameworks to address various big data challenges. Apache Hive, for instance, provides a SQL-like interface for querying and analyzing data stored in Hadoop, making it accessible to users familiar with relational databases.
Apache Pig, another component, offers a high-level platform for creating complex data processing pipelines using a scripting language called Pig Latin. This abstraction simplifies the development of data transformation tasks, enabling faster iteration and experimentation.
For real-time data processing needs, Apache Spark emerges as a powerful alternative to MapReduce. Spark provides in-memory processing capabilities, significantly accelerating data processing tasks and reducing latency.
Moreover, Apache HBase, a distributed, scalable NoSQL database built on top of Hadoop, enables random, real-time access to data stored in HDFS. It is particularly well-suited for applications requiring low-latency reads and writes, such as those in the realm of Internet of Things (IoT) and sensor data analytics.
In addition to these components, the Hadoop ecosystem encompasses tools for data ingestion, workflow management, and cluster orchestration, such as Apache Flume, Apache Oozie, and Apache Ambari, respectively.
Overall, the Hadoop ecosystem offers a robust and flexible platform for processing and analyzing big data at scale. By leveraging its diverse set of tools and frameworks, organizations can derive valuable insights from their data assets, driving informed decision-making and gaining a competitive edge in today’s data-centric landscape.
Introduction
In today’s digital landscape, the amount of data being generated is increasing at an exponential rate. This has led to the emergence of big data, a term used to describe large and complex data sets that traditional data processing tools are unable to handle. To manage and analyze these massive datasets, a powerful and efficient system is required. This is where Hadoop ecosystem comes into play.
What is Hadoop?
Hadoop is an open-source software framework used for distributed storage and processing of large datasets across clusters of computers. It was initially developed by Doug Cutting and Mike Cafarella in 2006 and was named after Cutting’s son’s toy elephant. Hadoop’s design is based on a simple programming model called MapReduce, which allows for parallel processing of large sets of data.
Hadoop Components
The Hadoop ecosystem is made up of four main components: Hadoop Common, Hadoop Distributed File System (HDFS), Hadoop MapReduce, and Hadoop YARN.
Hadoop Common provides the libraries and utilities needed to run Hadoop. It consists of the core libraries, utilities, and the necessary files and scripts used by other Hadoop modules.
HDFS is a distributed file system that can handle large datasets by distributing them across multiple machines. The data is also replicated, making it fault-tolerant and accessible even if a node in the cluster fails.
Hadoop MapReduce is a programming model used to process and analyze large datasets in parallel. It divides the input data into smaller chunks and distributes them across the cluster for processing. Once the processing is complete, the results are combined to produce the final output.
Hadoop YARN (Yet Another Resource Negotiator) is the resource management tool of Hadoop. It manages the processing resources in the cluster and schedules tasks to be executed on the nodes.
Other Hadoop Ecosystem Technologies
Apart from the four main components, the Hadoop ecosystem also consists of several other technologies that complement and extend its capabilities. These include:
1. HBase: A distributed, column-oriented database capable of handling both structured and unstructured data.
2. Pig: A data flow language used to analyze large datasets.
3. Hive: A data warehouse infrastructure built on top of Hadoop, which provides a SQL-like interface for querying and managing large datasets.
4. Spark: An open-source, fast, and general-purpose engine for large-scale data processing.
5. Mahout: A distributed machine learning framework built on top of Hadoop, used for creating scalable machine learning algorithms.
Benefits of Hadoop Ecosystem
The Hadoop ecosystem is popular among organizations dealing with big data because of the following advantages:
1. Cost-Effective: Hadoop is built on commodity hardware, making it more affordable than traditional data processing tools.
2. Scalability: Hadoop allows for the addition of more nodes to the cluster, making it highly scalable and able to handle petabytes of data.
3. Fault-Tolerant: As data is replicated and distributed across multiple nodes, if one node fails, the data is still accessible from other nodes.
4. Flexibility: The variety of components in the Hadoop ecosystem make it highly flexible, allowing organizations to customize and build solutions that fit their specific needs.
Challenges of Hadoop Ecosystem
While the Hadoop ecosystem has numerous benefits, it also poses some challenges. These include:
1. Learning Curve: As Hadoop is a relatively new technology, the learning curve for developers can be steep.
2. Skill Gap: There is a shortage of skilled professionals who are proficient in Hadoop and related technologies.
3. Maintenance: Hadoop requires ongoing maintenance, which can be time-consuming and costly.
Conclusion
In conclusion, the Hadoop ecosystem has revolutionized the way organizations manage and analyze big data. Its scalability, flexibility, and cost-effectiveness have made it a popular choice among businesses dealing with large datasets. With the continuous development and improvement of its components, the Hadoop ecosystem is set to play a vital role in the future of big data. As the amount of data being generated continues to grow, Hadoop will be crucial in ensuring that organizations can extract valuable insights and drive innovation.