Hive architecture in big data: In the realm of big data, Hive architecture plays a vital role in managing and analyzing vast amounts of data efficiently. Let’s delve into what Hive architecture entails and how it operates within the big data landscape.
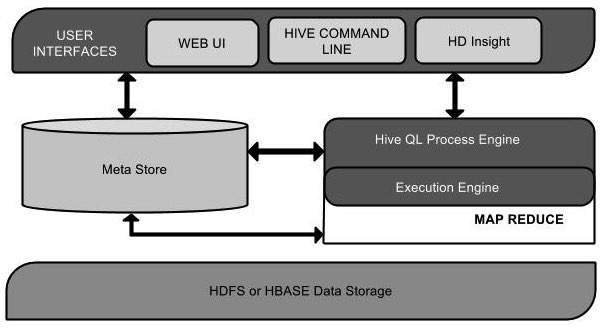
Hive is a data warehousing infrastructure built on top of Hadoop. It provides a mechanism to query and analyze data stored in Hadoop Distributed File System (HDFS) using a SQL-like language called HiveQL. Essentially, Hive acts as a bridge between the Hadoop ecosystem and traditional SQL-based tools.
At the core of Hive architecture lies the metastore, which stores metadata such as table schemas, column types, and their corresponding locations in HDFS. This metadata is crucial for query optimization and execution.
One of the key components of Hive architecture is the Hive Query Language (HiveQL), which resembles SQL. Users can write queries in HiveQL to perform various operations on the data stored in HDFS. These operations include data manipulation, filtering, aggregation, and joining.
Hive architecture comprises several components working together to process and analyze data effectively. The Hive Metastore stores metadata, the Query Compiler translates HiveQL queries into execution plans, and the Execution Engine executes these plans on Hadoop clusters.
Another essential aspect of Hive architecture is its support for partitioning and bucketing. Partitioning allows data to be organized into directories based on specific criteria, such as date or region, which improves query performance by reducing the amount of data scanned.
Bucketing further enhances performance by dividing data into smaller, more manageable units based on hash functions.
Furthermore, Hive supports various file formats, including text, Parquet, ORC, and others. Each file format has its advantages in terms of compression, query performance, and compatibility with different data processing frameworks.
In summary, Hive architecture in big data provides a structured and efficient way to manage and analyze large datasets stored in Hadoop clusters. By leveraging Hive’s SQL-like interface, users can easily query and process data using familiar tools and techniques, making big data analytics more accessible and scalable.
Hive architecture, a key component in big data, has become an essential tool for businesses and organizations to efficiently process and analyze large amounts of data. This architectural framework has revolutionized the way data is managed, providing a scalable, fault-tolerant and cost-effective solution for handling massive data sets.
At its core, Hive is a data warehousing infrastructure built on top of Hadoop, an open-source distributed computing framework. Hive uses a high-level language called HiveQL (a variation of SQL), which allows users to write SQL-like queries to interact with data stored in Hadoop Distributed File System (HDFS). With its ability to store, manage and process large amounts of data, Hive has become the go-to choice for businesses looking to leverage big data for decision making.
The architecture of Hive is divided into three components – user interface, metastore and execution engine. The user interface provides an interactive command-line shell, a web interface and a JDBC driver for developers to interact with Hive. The metastore serves as a central repository for storing metadata (table and partition definitions, schema information, etc.) of all the data stored in Hive. Finally, the execution engine is responsible for processing the queries and converting them into a series of MapReduce jobs for execution on the Hadoop cluster.
One of the biggest advantages of Hive is its ability to handle structured and semi-structured data, making it a versatile tool for a wide range of data processing tasks. Unlike traditional databases where data has to be predefined with a schema, Hive allows for on-the-fly schema creation, which makes it suitable for storing and analyzing unstructured data such as logs, social media feeds, etc.
Moreover, Hive supports a wide range of data formats and is compatible with a variety of tools and programming languages, making it a highly flexible and customizable solution. It also allows for the integration of user-defined functions and libraries for advanced data processing and analysis.
Apart from its powerful features, Hive architecture also offers robust fault tolerance, scalability and cost-effectiveness. With its ability to run on commodity hardware, it significantly reduces the overall cost of storage and processing for organizations. Additionally, Hive is designed to handle large datasets efficiently, making it a highly scalable solution for enterprises that deal with ever-growing amounts of data.
In conclusion, Hive architecture has played a vital role in the adoption and success of big data technologies. Its simplicity, versatility, fault tolerance, scalability and cost-effectiveness make it a preferred choice for organizations looking to harness the potential of big data. With its continuous evolution and development, Hive is poised to remain a vital component in the ever-expanding world of big data.